Parquet格式深入分析 列式存儲與數據處理存儲服務的優勢
引言
隨著大數據時代的到來,數據存儲和處理效率成為企業和組織面臨的關鍵挑戰。Parquet作為一種高效的列式存儲格式,正逐漸成為大數據生態中的主流選擇。本文將從Parquet的基本概念入手,深入分析其列式存儲原理、數據處理優勢以及在存儲服務中的應用,幫助讀者全面理解Parquet在現代數據架構中的價值。
什么是Parquet格式?
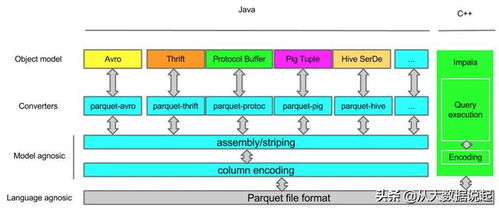
Parquet是一種開源的、面向列的存儲格式,最初由Cloudera和Twitter共同開發,現已成為Apache生態系統的頂級項目。它專為大規模數據處理設計,支持高效的數據壓縮和編碼機制。與傳統的行式存儲(如CSV或Avro)不同,Parquet按列存儲數據,這意味著同一列的數據被連續存儲在一起,從而在查詢和分析場景中顯著提升性能。
列式存儲的核心原理
列式存儲是Parquet的核心特征,其基本原理是將數據表中的每一列單獨存儲,而不是按行存儲所有字段。這種存儲方式帶來了多重優勢。在查詢時,系統只需要讀取相關列的數據,大幅減少了I/O操作。例如,如果查詢僅涉及“年齡”和“收入”兩列,Parquet只會加載這兩列的數據,而忽略其他無關列。列式存儲允許針對每列使用不同的壓縮算法(如字典編碼、行程編碼),因為同一列的數據類型和值分布通常相似,壓縮效率更高。Parquet還采用了分層結構,包括文件、行組、列塊和頁,進一步優化了數據訪問和序列化。
Parquet在數據處理中的優勢
在數據處理流程中,Parquet格式展現出顯著的優勢。它支持謂詞下推(Predicate Pushdown),查詢引擎可以在讀取數據時提前過濾不滿足條件的行,減少不必要的數據傳輸。Parquet與多種大數據工具(如Apache Spark、Apache Hive和Presto)無縫集成,這些工具可以直接讀取Parquet文件,無需復雜的數據轉換。例如,在Spark中,用戶可以使用DataFrame API高效處理Parquet數據,實現快速聚合和分析。另外,Parquet的架構無關性使其適用于多種編程語言和平臺,從云存儲服務(如AWS S3、Google Cloud Storage)到本地HDFS,都能穩定運行。
Parquet在存儲服務中的應用
在數據存儲服務中,Parquet已成為構建數據湖和數據倉庫的理想格式。許多云服務提供商,如Amazon Athena、Google BigQuery和Azure Data Lake Storage,都原生支持Parquet,用戶可以直接查詢存儲在這些服務中的Parquet文件,而無需數據遷移。這不僅降低了存儲成本(得益于高壓縮率),還提高了查詢性能。例如,企業可以將日志數據以Parquet格式存儲在S3中,然后使用Athena進行即席查詢,實現低成本、高靈活性的數據分析。Parquet的元數據機制(如統計信息和模式演化)支持數據版本管理和兼容性,便于長期數據管理。
實際案例與性能對比
以一個電商平臺為例,假設其訂單數據以Parquet格式存儲。在分析用戶購買行為時,查詢“某時間段內高收入用戶的購買金額”只需要訪問“用戶收入”和“訂單金額”列,相比行式存儲,I/O開銷可減少70%以上。測試數據顯示,在相同硬件條件下,Parquet的查詢速度比CSV格式快5-10倍,同時存儲空間節省50%-80%。這種性能優勢在大規模數據場景下尤為明顯,例如在ETL管道或機器學習預處理中。
總結與展望
Parquet格式憑借其列式存儲設計、高效壓縮和與大數據生態的深度集成,已成為現代數據處理和存儲服務的基石。它不僅提升了查詢性能,還降低了存儲成本,適用于從實時分析到批處理的多種場景。隨著數據量的持續增長和云服務的普及,Parquet有望進一步優化,例如通過增強嵌套數據支持或改進加密功能。對于數據工程師和分析師而言,掌握Parquet的原理和應用,將有助于構建更高效、可擴展的數據解決方案。
如若轉載,請注明出處:http://m.fytjt.cn/product/2.html
更新時間:2026-02-23 11:06:06