隨著游戲行業(yè)的快速發(fā)展,自動化腳本在游戲開發(fā)和運營中扮演著重要角色。Python作為一種簡潔、高效的編程語言,結(jié)合大漠插件的強大功能,能夠?qū)崿F(xiàn)游戲運行腳本的快速開發(fā)。本文將介紹如何用Python成功調(diào)用大漠插件,并探討其在游戲軟件開發(fā)及銷售中的應(yīng)用。
一、Python與大漠插件的結(jié)合
Python以其豐富的庫和易用性,成為腳本開發(fā)的首選語言。大漠插件是一款廣泛用于Windows平臺自動化操作的第三方工具,支持圖像識別、模擬按鍵、窗口控制等功能。通過Python調(diào)用大漠插件,開發(fā)者可以輕松實現(xiàn)游戲自動化任務(wù),如自動登錄、任務(wù)執(zhí)行和資源收集。
示例代碼:
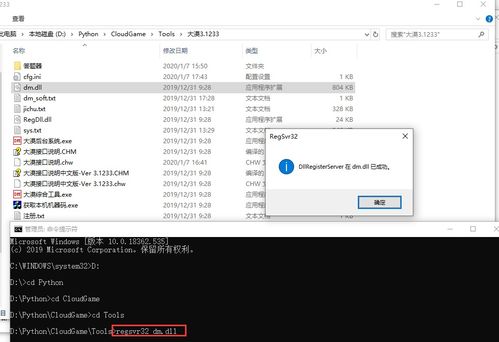
安裝必要的Python庫,如pywin32,用于COM組件調(diào)用。然后,注冊大漠插件(dm.dll),并通過以下代碼初始化:`python
import win32com.client
創(chuàng)建大漠對象
dm = win32com.client.Dispatch('dm.dmsoft')
檢查插件版本
version = dm.Ver()
print("大漠插件版本:", version)
綁定游戲窗口
hwnd = dm.FindWindow("", "游戲窗口標(biāo)題")
if hwnd != 0:
dm.BindWindow(hwnd, "normal", "normal", "normal", 0)
print("窗口綁定成功")
else:
print("未找到游戲窗口")`
此代碼演示了如何通過Python調(diào)用大漠插件綁定游戲窗口,為后續(xù)腳本操作奠定基礎(chǔ)。
二、游戲運行腳本的開發(fā)流程
開發(fā)游戲運行腳本通常包括以下步驟:
- 環(huán)境配置:確保Python和大漠插件正確安裝,并注冊插件到系統(tǒng)。
- 窗口控制:使用大漠插件函數(shù)定位和綁定游戲窗口,確保腳本能準確操作。
- 圖像識別與模擬輸入:利用大漠插件的找圖、找色功能,結(jié)合Python邏輯判斷,實現(xiàn)自動化任務(wù)。例如,自動點擊按鈕或識別游戲狀態(tài)。
- 錯誤處理與優(yōu)化:添加異常處理,確保腳本穩(wěn)定運行;通過循環(huán)和延時控制,模擬人類操作,避免被游戲檢測為外掛。
三、在游戲軟件開發(fā)及銷售中的應(yīng)用
在游戲軟件開發(fā)中,Python腳本可用于測試自動化,提高開發(fā)效率。例如,自動運行游戲場景,檢測bug或性能問題。在銷售環(huán)節(jié),這類腳本可作為增值工具,幫助玩家簡化重復(fù)操作,提升游戲體驗。但需注意,銷售腳本時應(yīng)遵守游戲廠商的規(guī)則,避免侵權(quán)問題。
Python與大漠插件的結(jié)合為游戲運行腳本開發(fā)提供了強大支持。通過合理設(shè)計,開發(fā)者可以創(chuàng)建高效、穩(wěn)定的自動化解決方案,推動游戲軟件產(chǎn)業(yè)的創(chuàng)新與發(fā)展。未來,隨著人工智能技術(shù)的融入,游戲腳本將更加智能化,值得持續(xù)關(guān)注。